Automated Large-Scale Sensor Fusion
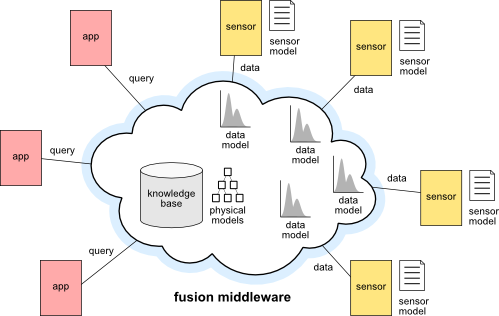
Figure: System overview.
The vision in this project is to develop a general sensor fusion middleware, which can autmatically compose the required sensors to provide information that cannot be gathered from any single sensor in the network.
Currently, any system that fuses data from multiple sensors must be carefully designed by an expert, and can only fulfill a limited number of application-specific roles. In this process, it is up to this expert to collect — and often “guesstimate” — probability distributions, tweak model parameters, calibrate sensors, extract sensor registration parameters, and so on.
Clearly, that approach does not scale.
Even worse, as the size of sensor networks continues to grow into the billions we will find that sensors age and lose calibration, and more often than not the metadata that they carry is either incomplete or erroneous. Therefore, it is safe to say that automated sensor fusion techniques will quickly become a necessity in future sensor networks, mixing estimation theory with data mining in order to overcome the growing amounts of missing information.
In this project, I investigated the creation of a general sensor fusion middleware that can answer a wide range of sensory questions given little or no a priori knowledge regarding the sensors that exist in the network. The goal of this project is twofold: first, it aims to enable networks that grow organically by simply plugging new sensors; But, equally importantly, this project also strives to give users and application developers the power to interact with sensor networks about which they know nothing, by making high-level queries rather than dealing with deployment-specific details such as node IDs, available sensors, individual node locations, etc. It is up to the middleware, then, to answer these queries by composing the available sensors, transforming their data, and making temporal predictions or spatial estimations. For this, the system will leverage three types of information: (1) an ontology of physical phenomena; (2) a sensor model containing (possibly imprecise or incomplete) metadata about each sensor, such as manufacturer, model, location, and calibration parameters; (3) a learned data model consisting of the observed probability distribution of the data, and perhaps even cross-dataset information such as joint probabilities, covariances, or cross-correlations.
This work was done in close collaboration with Sarah Hachem, Animesh Pathak, Nikolaos Georgantas, and Valérie Issarny's — the same people who are now continuing the project in my absence. So keep an eye on them for more developments!
Related:
Survey of Human Sensing
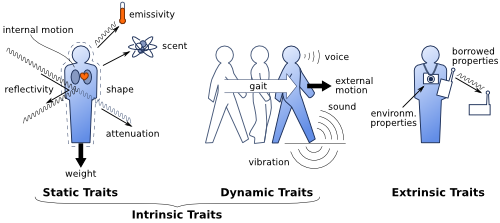
Figure: Measurable “Human Traits”.
Illustration of the physical traits that can be used to sense information related to people in an environment. Human-sensing approaches exploit at least one of these traits, and often a combination thereof.
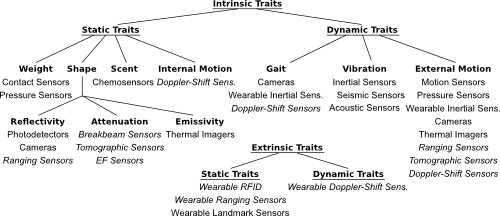
Figure: Taxonomy of traits and modalities.
This is the taxonomy of measurable human traits that I describe in my human-sensing survey. Below each trait is a list of sensing modalities that can detect it. Italics are used to denote active signaling sensors, and the word wearable indicates instrumented approaches.
An increasingly common requirement of computer systems, from smart phones to smart rooms, is to extract information regarding the people present in an environment — or what is called “Human Sensing”.
There currently exist a multitude of sensors and systems oriented toward human sensing, and they can often provide a very distinct set of services. For instance, some can detect human presence, but cannot count or localize them; Others count and localize, but cannot tell a person from another foreign object. And although there are a number of papers describing these approaches, they are usually too specific, concerned with comparisons within specific sensing modalities, such as solely cameras, or solely wearable nodes. As a result, researching, and let alone finding out about, what is out there can be an arduous task.
So I thought I might as well share our human sensing survey here, and save people from a lot of time and frustration :) . In this survey we gather over 100 human sensing approaches and compare them under a common classification system, in an attempt to make sense of it all. I hope this proves as useful to others as it has been to me!
Related:
Multiple-Person Identification
with Multimodal Sensor Networks
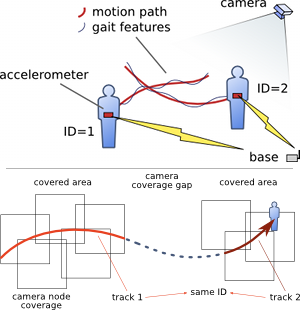
Figure 1: System overview.
People carrying wearable nodes can be identified by matching motion or gait features from the wearable nodes with those detected with the camera network. The proposed identification method is capable to withstand gaps in coverage.
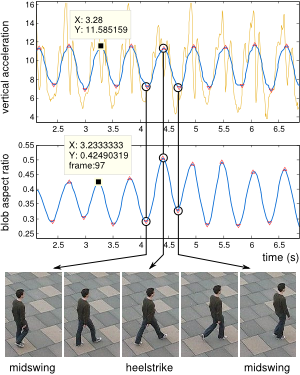
Figure 2: Extraction of gait features.
We detect motion and gait features from both cameras and accelerometers. Motion features are “turning” and “moving/stopping” while gait features are “heel-strike” and “midswing” instants of gait. A person in the video is identified when the track’s motion signature (the timestamps of the triangle markers on the plot) matches that of some accelerometer in the scene.
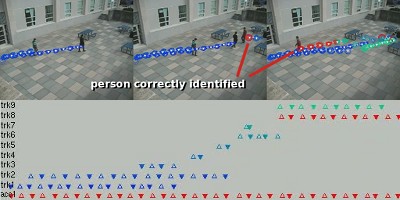
Figure 3: Example output frames.
The figure shows three frames where people’s tracks are overlaid on the image either in red or blue. Red indicates that the system has made a decision regarding the tracked person’s ID, while blue stands for no identification. In this experiment, only one person was carrying a wearable node, and he was correctly identified by the system. An error-prone nearest-neighbor tracker (OpenCV) was used here to show that people are correctly identified even in the presence of track discontinuities (which occur when two people meet). A better tracker (based on the mean-shift algorithm) fares much better.
Identifying people in sensor networks is a stepping-stone for a number of high-level problems to become feasible in real-world, multiple-person scenarios. In our own behavior-recognition projects (see below), for example, if the traces of each occupant of a home can be separated and uniquely labelled then our current single-person activity recognition methods can be employed individually on each labelled trace, with little or no modification to the existing algorithms.
In this project we consider different methods of obtaining the ID of tagged people in smart camera networks. Each person of interest wears a sensor node equipped with inertial sensors (accelerometers, gyroscopes, magnetometers). Then by matching the motion signatures measured from the wearable sensors with the motion signatures extracted from the video we are able to identify each person with the wearable node’s ID.
In the video above, three people walk within the camera field-of-view, while only one of them carries a wearable accelerometer node. After the person with the wearable node walks a few steps, the system is able to identify him by comparing the gait signature observed by the accelerometer with that observed on the video. (In these examples, the person carrying the accelerometer node is always the one with the red jacket.)
Related:
Real-Time Human Localization
and Tracking in Smart Camera Networks
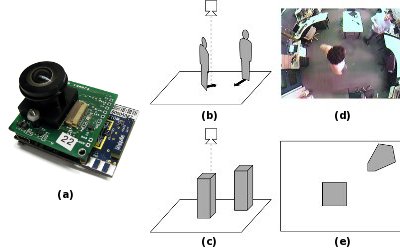
Figure 1: System overview.
Each of our custom camera nodes (a) is placed on the ceiling, facing down (b). The nodes look for the locations where the motion patterns in the image best match the cuboid model of a person (c). For the image in (d), for example, the best match is shown in (e).
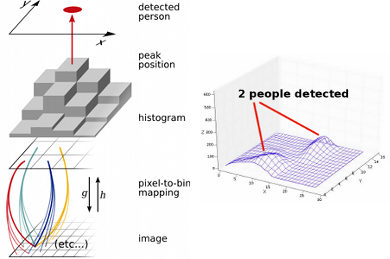
Figure 2: Histogram generation.
Left: The cuboids in the image map to bins in a histogram. People are detected at the histogram peaks. Right: Example histogram from a scene where two people have been detected.

Figure 3: Prototype network.
The figure shows a composite of 6 images acquired during the installation of a prototype network at ENALAB. The orange circles represent the 6 different nodes in the network (with their IDs), and the blue circles indicate that 3 different people have been detected. The numbers inside the blue circles are temporary IDs assigned to each person.
The two most common design parameters in sensor networks are that the sensor nodes must be cheap, and must operate within a limited energy budget. Together, these parameters translate to limited local processing capability — often less than can be found even in a standard cellular phone. For camera networks, this limitation is especially challenging: the last decades of computer vision have focused mostly on complex algorithms that cannot execute in real-time even on desktop machines. Although Moore’s law suggests that future sensor nodes will be able to detect people in videos in real-time, the other side of Moore’s law also points to hardware-miniaturization while maintaining today's processing limitations. In addition, a more immediate solution is needed for current real-world systems, such as our own assisted-living deployments.
In this work, we design a lightweight person-detection method that deals with these limitations by enforcing simplifying constraints on our deployment’s physical arrangement. By placing our wide-angle camera nodes on the ceiling, facing straight down, we can safely assume certain bounds on each person’s size (given that the ceiling height is known). Then, using a cuboid model of a human, we create a histogram representing the likelihood that a moving person is present at a certain location in the image. Each moving person can, thus, be detected by locating the modes of the histogram. Since this method is based on motion-differencing rather than background-subtraction, there are no lasting phantom-detections, such as arise when the background model fails to adapt to changes in the scene. This allows us to detect the location of moving people in our deployments with little maintenance or calibration.
Related:
BehaviorScope
Human Activity Recognition
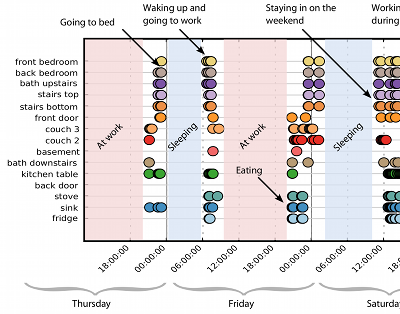
Figure 1: Raw collected location data.
The position of each person in a house is collected in the form of high-level locations, such as “couch”, “stove” and “kitchen table”. These are examples of “phonemes” of our behavior-parsing grammar.
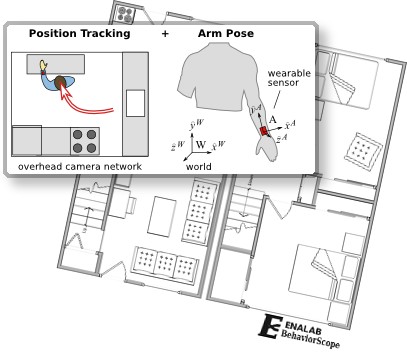
Figure 2: Locations and Arm poses.
The location of each person is obtained using ceiling-mounted cameras that detect the coordinates of each person and places them in the context of a building map containing pre-marked areas of interest. To obtain a finer level of granularity in the activity recognition framework, we have also considered inferring each person’s arm post through inertial sensors attached to their wrist.
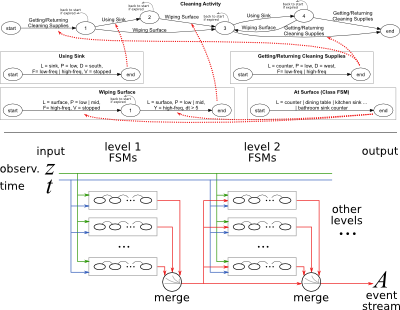
Figure 3: Hierarchy of State Machines.
A hierarchy of FSMs can be used in place of context-free grammars for increased control of timing properties of activities. Top: Example FSM for “Cleaning Activity”. Bottom: Block diagram of the hierarchy of FSMs. Each level’s output is redirected to the next level’s input stream. The hierarchy is organized in an object oriented manner and uses time constraints for increased robustness against errors.
In the BehaviorScope project we introduce a framework that recognizes human activities with a sensor-agnostic engine. The sequence of locations of people in a house are input into a probabilistic context-free grammar (PCFG) to detect behaviors. The inference project was led by Dimitrious Lymberopoulos, while I was in charge of building the sensor network infrastructure. The main challenge was to create a network of cameras that could extract locations of multiple people in real time, unattended, in several-month-long home deployments.
In addition to sequences of locations, I have also investigated the use of wristband-style inertial sensors to extract arm-pose information for finer-grained activity interpretation. In order to withstand the large numbers of false-positive noise that we noticed in our long-term deployments, this system makes use of finite state machines (FSMs) enhanced with time bounds on each transition. The FSMs are layered into a multi-level hierarchy that can parse human activites in real time on commodity hardware.
Related:
Address-Event Imaging for Sensor Networks
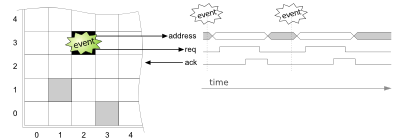
Figure 1: Overview of Address-Event Imager.
In an Address-Event imager, each pixel acts as an independent feature-detector that sends a pulse to indicate a detection (i.e. an “event”). These get multiplexed into a bus by translating each pulse pulse into an address (the address of the source pixel). Hence the name “address-event”.
Figure 2: Sensor Node and Emulator
Here we see a picture of the Address-Event sensor node (front) and a screenshot of the Address-Event Emulator software that I developed (back).

Figure 3: Emulator output compared to imager output.
As seen in this image, the model used in the Address-Event Emulator software produces output comparable to that of the ALOHA AE imager.
Traditional image sensors communicate sequentially, from top-left to bottom-right, the intensity of the light measured at each pixel in a process called “scanning”. This leads to images that are represented as arrays of intensity values. While such a representation has many qualities, such as compactness and ease of display, it is not particularly friendly for data interpretation purposes.
In response to this, Address-Event (AE) imagers take a cue from biological systems and measure the world, instead, through multiple asynchronous smart pixels that produce a pulse (or “spike”) when they encounter particular features such as motion or edges. Similar to the human brain, these sequences of spikes work as building blocks for high-level data interpretation. In my work I have built proof-of-concept sensor boards that utilize Prof. Eugenio Culurciello’s prototype AE imagers. I have also demonstrated a simple pattern-matching algorithm that can operate in the computationally constrained setting of a sensor node, and fares well against similar algorithms for traditional imagers. To facilitate the development of this and other AE algorithms, I wrote an Address-Event Emulator application for Windows that converts live video from webcams into AE streams. This application is provided free of charge here.